"You build it, you run it."
- Werner Voegls, CTO at Amazon Web Services
At Virginia Tech, running a Containers-as-a-Service (CaaS) platform is tough because of the spread of users. Even within our Central IT organization, we have many departments, who almost all act as individual business entities, rather than a single entity with separate parts. That doesn't even include the other departments and colleges distributed around the university. So, instead of having a centralized ops unit that will run all apps, we are seeking to provide a centralized container hosting platform where we can give as much control back to individual teams as possible. Obviously, this comes with some complexity.
Goals for the Container Service
- Provide ability to run containers - duh, right? We'd like to allow anyone to run any app, as long as its packaged up in a container. Truthfully, we shouldn't care about what's in it (assuming it meets the university's acceptable use policies).
- Have full auditability around what's running - we'd like to know 1) what's running when and 2) who requested/made changes to what's running. While this includes what is running, it should extend to changes in resource constraints, volumes mounted, secrets used, etc.
- Let individual teams deploy without hindrance - we'd like to allow customers to deploy without needing to submit tickets or getting the ops team involved. The more they can do, the faster they can deploy and the less we become a bottleneck.
- Protect the service and customers - if we give customers control, we want to ensure that they don't step on each other's toes, whether accidentally or maliciously. For example, customer A shouldn't be able to mount customer B's volumes.
Leveraging "Service as Code"
We decided to leverage repos to keep track of the stacks in the cluster. These repos are small and contain only a single docker-stack.yml file. Why?
- Version control - version control gives us full auditability on who changed what when. Coupled with commit signing, we have greater assurance on the initial requestor.
- Master = Deployed State - leveraging best practices, the master branch reflects the current state in the cluster
- Automated builds - any changes to the master branch trigger a build in which the runner will deploy the updated stack file to the cluster
- Ability to request changes - want to change the current state? Any individual on the team can make a merge request against the current master branch. Once merged, the update will be automatically deployed.
- Easy permissioning - by leveraging a single repo per stack, it's easy to manage who has permissions to each repo. The CaaS team obviously has access to all, but each customer has only access to the repos for their stacks.
Each stack repo is owned by the CaaS team. With GitLab, the master branch is protected branch, so only the CaaS team can modify the master branch directly. The app-owning team members are added as "Developers" to the repo, so they can make branches and merge requests to update master.
The Deployment Process, Round One
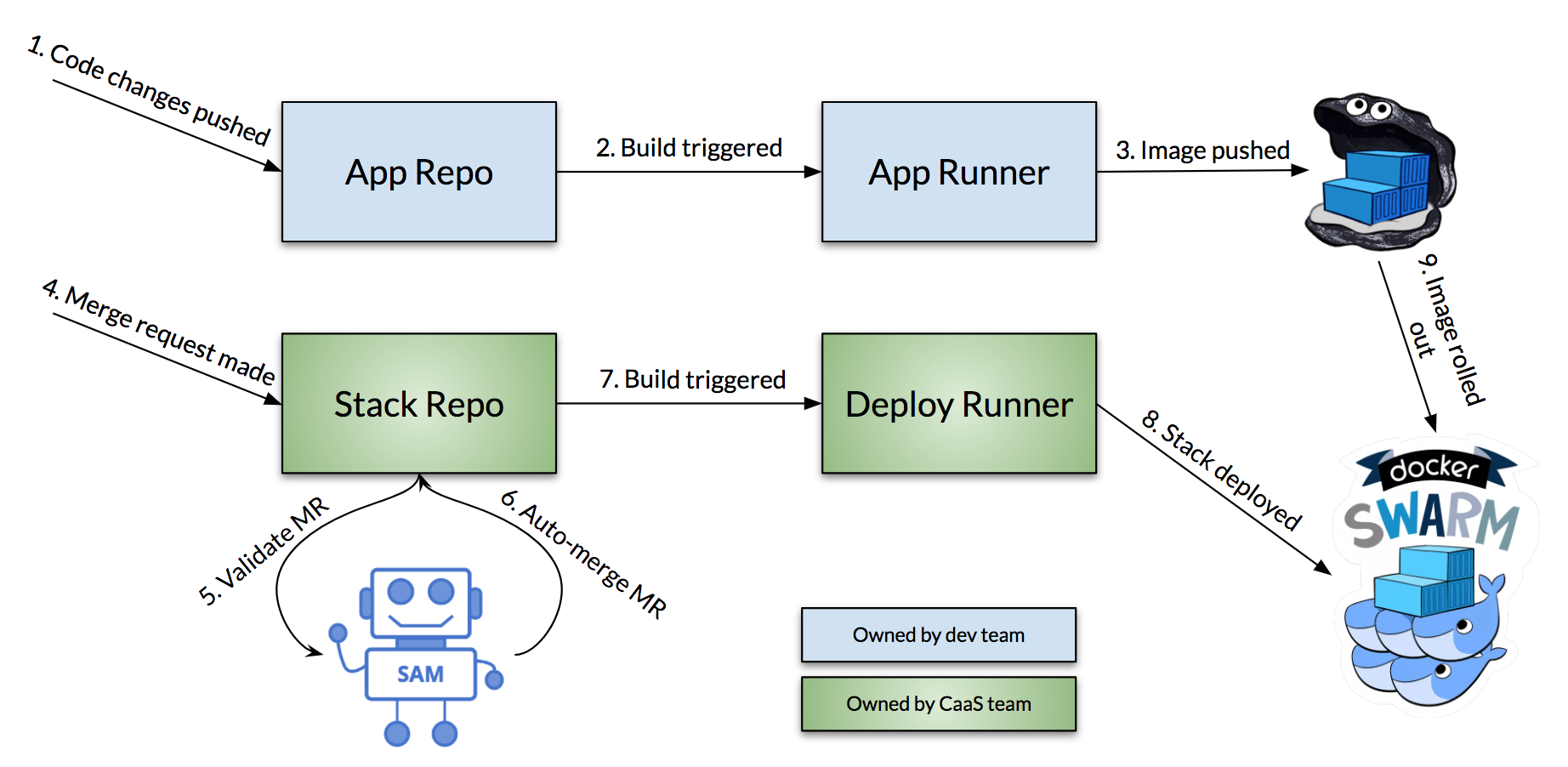
Our first attempt of the deployment process looked something like this…
- Development team writes and pushes code to repo (GitLab in our case)
- An automated build is triggered in which a new Docker image is created
- The new Docker image is pushed to DTR
- Dev team creates a new branch and MR requesting image change in the docker-stack.yml file
- CaaS team accepts the merge request
- Automated build is triggered.
- Updated stack is deployed to the cluster
BUT WAIT!

Right you are Fry!
Deployment Process, Round Two
We spent some time thinking about when a human actually needs to be involved. If a team is only updating the image (pushing an update), why should the CaaS team need to sign off on that? We decided they shouldn't need to. Teams should be able to update their own app. If they're changing volumes, resource constraints, etc., then it makes sense to have a pair of eyes verify the request.
Back in December, I prototyped the ability to use a webhook that receives notifications of merge requests. It "validates" the merge request and, if valid, auto-merges the request. The first prototype merely looked at the diff patch made available in the GitLab MR API. While simple, it proved the point. We can do it.
Over the past week, I built the our Stack Auto Merging bot, simply named SAM. This bot is a more production-ready version of the prototype we tried earlier. And… it's open source on GitHub. So… say hi to SAM!

I'll write more about SAM in a follow-up post, but what SAM allows us to do is simplify the deployment process. Changes to the process are bolded…
- Development team writes and pushes code to repo (GitLab in our case)
- An automated build is triggered in which a new Docker image is created
- The new Docker image is pushed to DTR
- Dev team creates a new branch and MR requesting image change in the docker-stack.yml file
- SAM is notified of the request and performs validation.
- If SAM's validation is successful, it auto-merges the MR. Otherwise, the CaaS team reviews as normal.
- Automated build is triggered.
- Updated stack is deployed to the cluster
With this… dev teams can deploy updates to their services without getting ops involved at all. We're incredibly excited about this and hope you are too!
What about Docker EE?
I'm glad you asked! We are proud Docker EE customers. While they have a great RBAC scheme in place, it still isn't quite granular enough for what we need. Ideally, we'd like to give teams the ability to manage their services, but like mentioned above, limit the changes they can make. Some examples include:
- We can't limit their ability to modify service labels that might influence how HTTP traffic is routed (since we're currently using Traefik).
- We can't prevent the ability to change CPU/memory resource reservations. Since we're sharing nodes, we don't want to allow someone to consume all resources without being vetted first.
Despite this, we're still planning to give access to teams to use UCP to see their services, use the container console for debugging, etc. They just can't make changes via the UCP interface at this time.
Recap
By leveraging git repos for stack files, we maintain the ability to audit what's running in the cluster at any point of time. Any changes to the master branch triggers updates to be deployed. By utilizing merge requests, teams can request changes. If the change is simple, our SAM bot auto-accepts the merge request. Then, the CaaS team only needs to be involved for requests they should be involved with.
To learn more about SAM, check out the GitHub repo here or stay tuned for a more in-depth bost about SAM!
Questions?
Have any questions? Great! Feel free to reach out! While we're happy with what we've landed on, it doesn't mean we can't make it better. We haven't seen a lot of people writing about this journey yet, so we figured we'd write about what we've done and start the conversation.