Throughout the last few years, I've been fortunate to do lots of incredible things at Virginia Tech. But, I'll be honest when I say I'm probably most proud of what I'll be talking about in this post. Humbly, it's pretty slick!
Background and Goals
I've written about our QA setup before, but we've continued to evolve it over the years. About six months ago, we started to run into scaling problems, as we were running everything locally on a big single-node Swarm cluster. It worked great, but as we scaled up our team, we needed more and more concurrent stacks. We could have added nodes to our cluster, but we also wanted to move to the cloud.
Rather than lifting and shifting, we really wanted to figure out how to do it cloud-first. How can we leverage various AWS services? What new things can we learn? How do we manage our "infrastructure as code?" In addition, we had the following goals:
- Allow for almost limitless scale - we have no idea how many concurrent features we may be working on, but want to be able to scale
- Minimize cost as much as possible - how can we prevent paying for stacks that are sitting idle and not being used most of the time?
- Be quickly available - if we scale out a stack, how do we get it back as quickly as possible to minimize downtime for our QA testers?
As I presented what we've done to others, I realized the best way to convey the environment was through a story. So, enjoy the slider/carousel below!
-
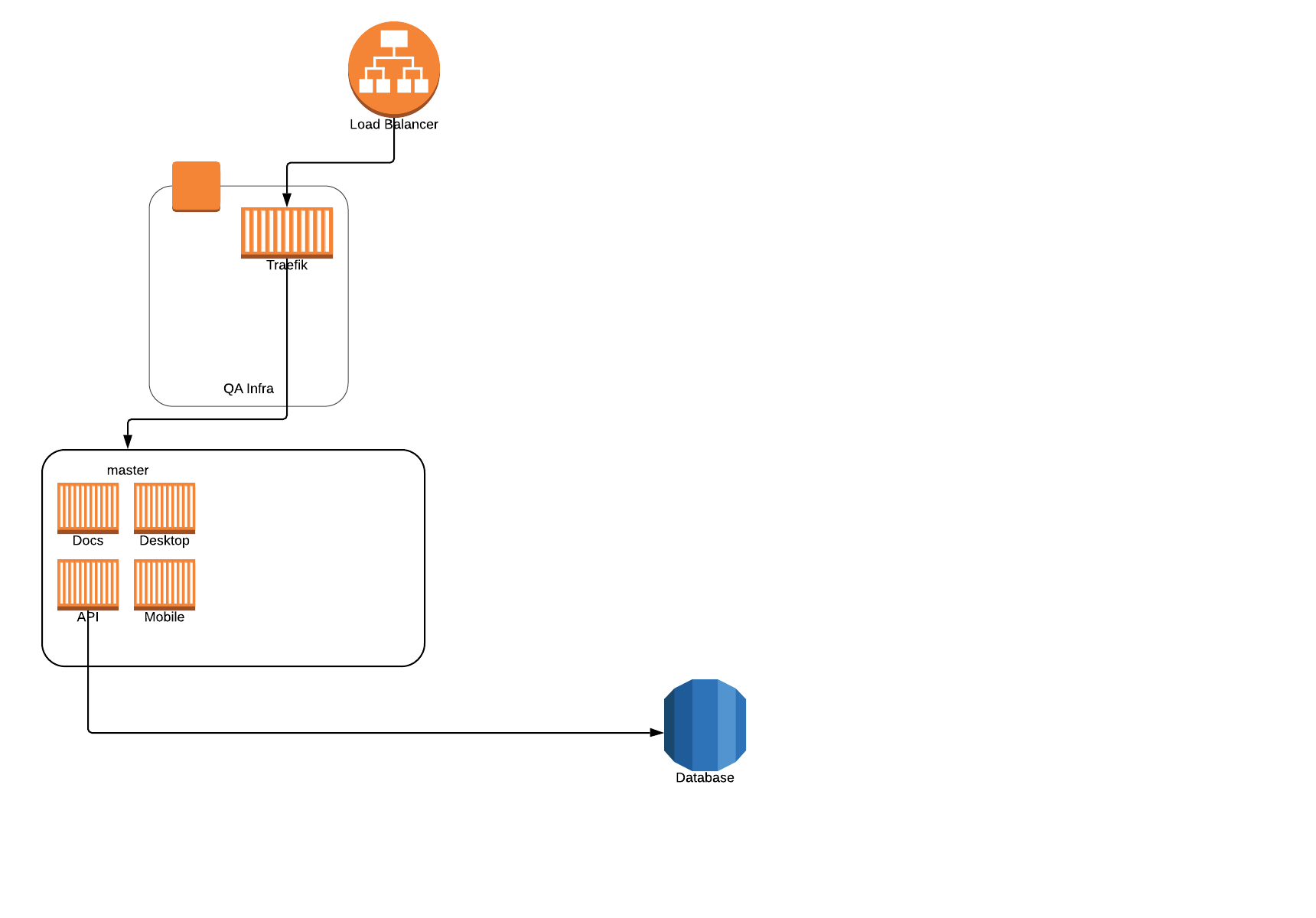
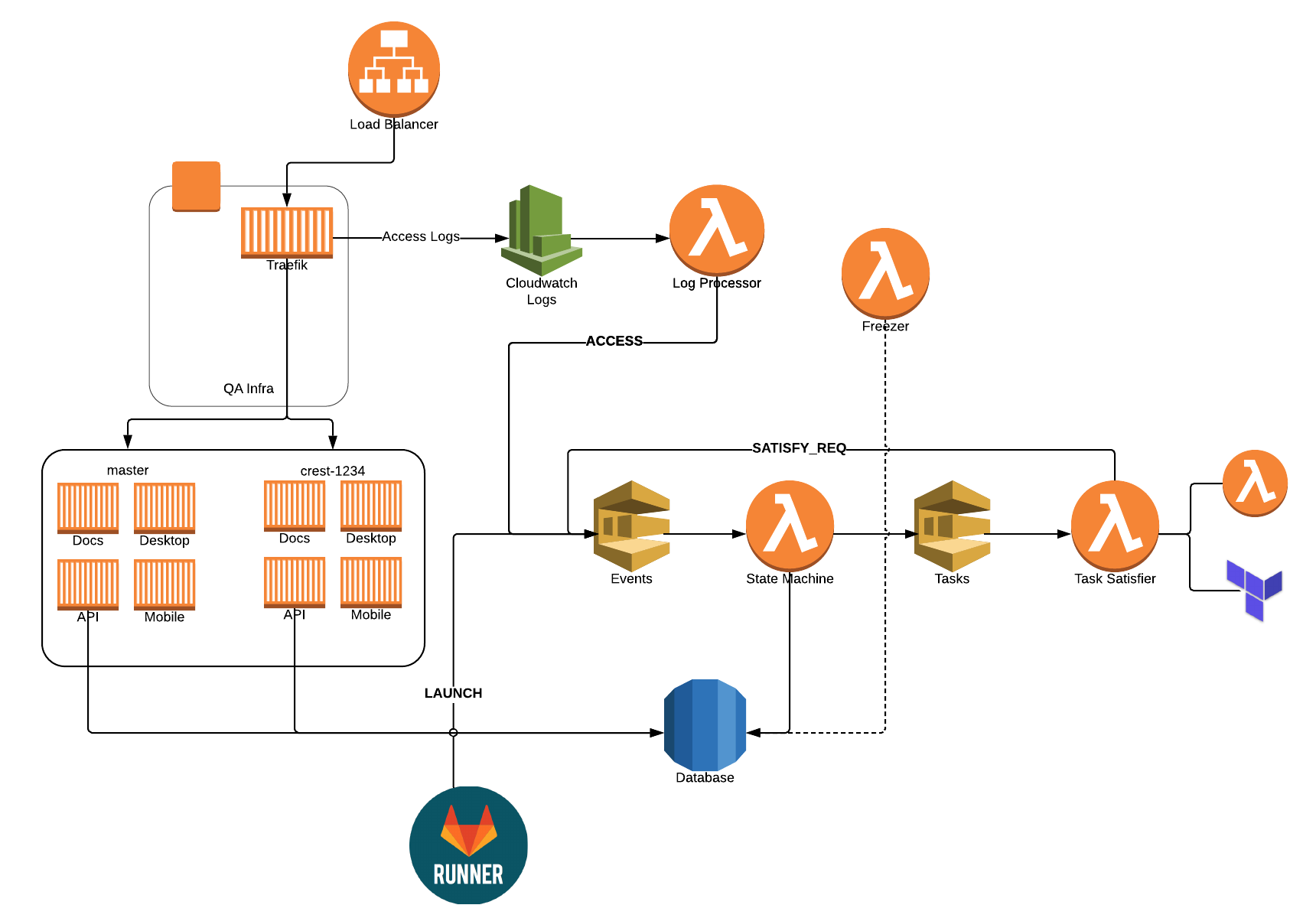
The overall architecture:
- An ALB sends traffic to an ECS service running Traefik
- Traefik is running in ECS mode, so polls ECS to update its routing config
- Stack containers are running in Fargate
- The API container requires PostgreSQL (RDS)
-
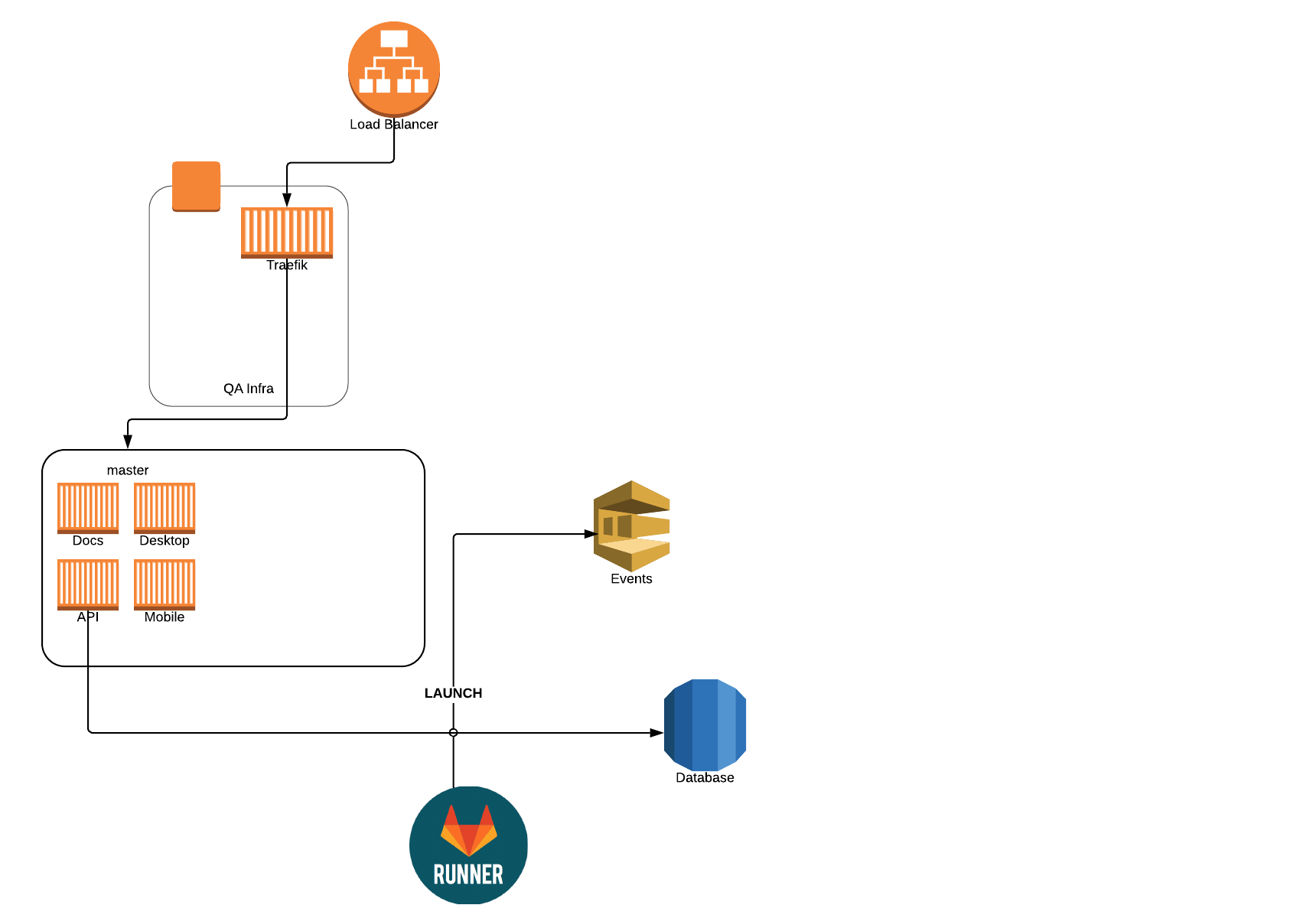
When we need a new stack, our build pipeline sends a message to an "events" queue in SQS, with the following properties:
stackId- the stack being deployedaction- the action for the state machine ("LAUNCH" in this case)- The image tags to use for each container
-
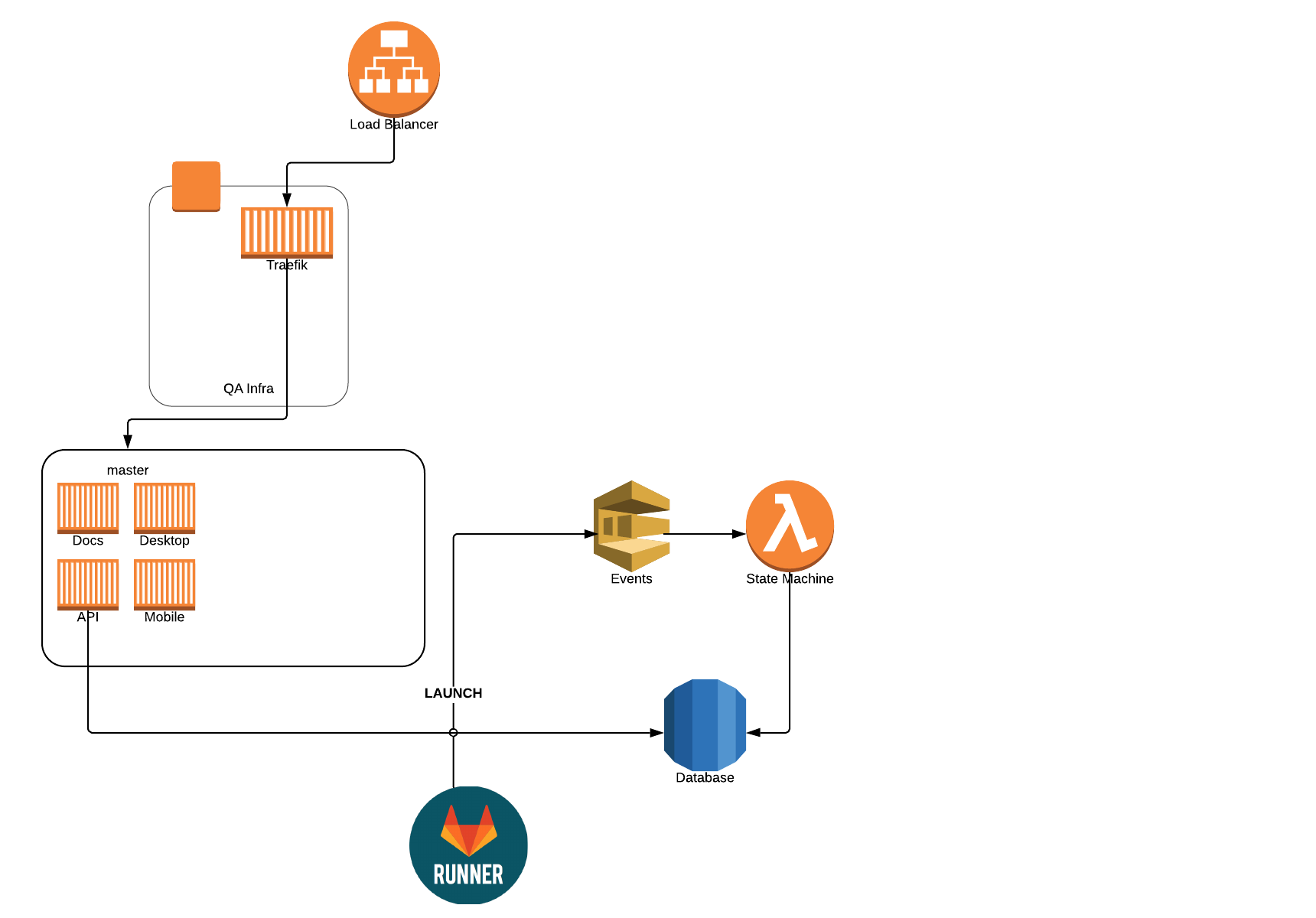
On the other side of the queue is a Lambda function. Basically, it's a state machine (depicted below) and determines how to respond to the event.
Since we are already using RDS for our stacks, we store our function state there as well.
-
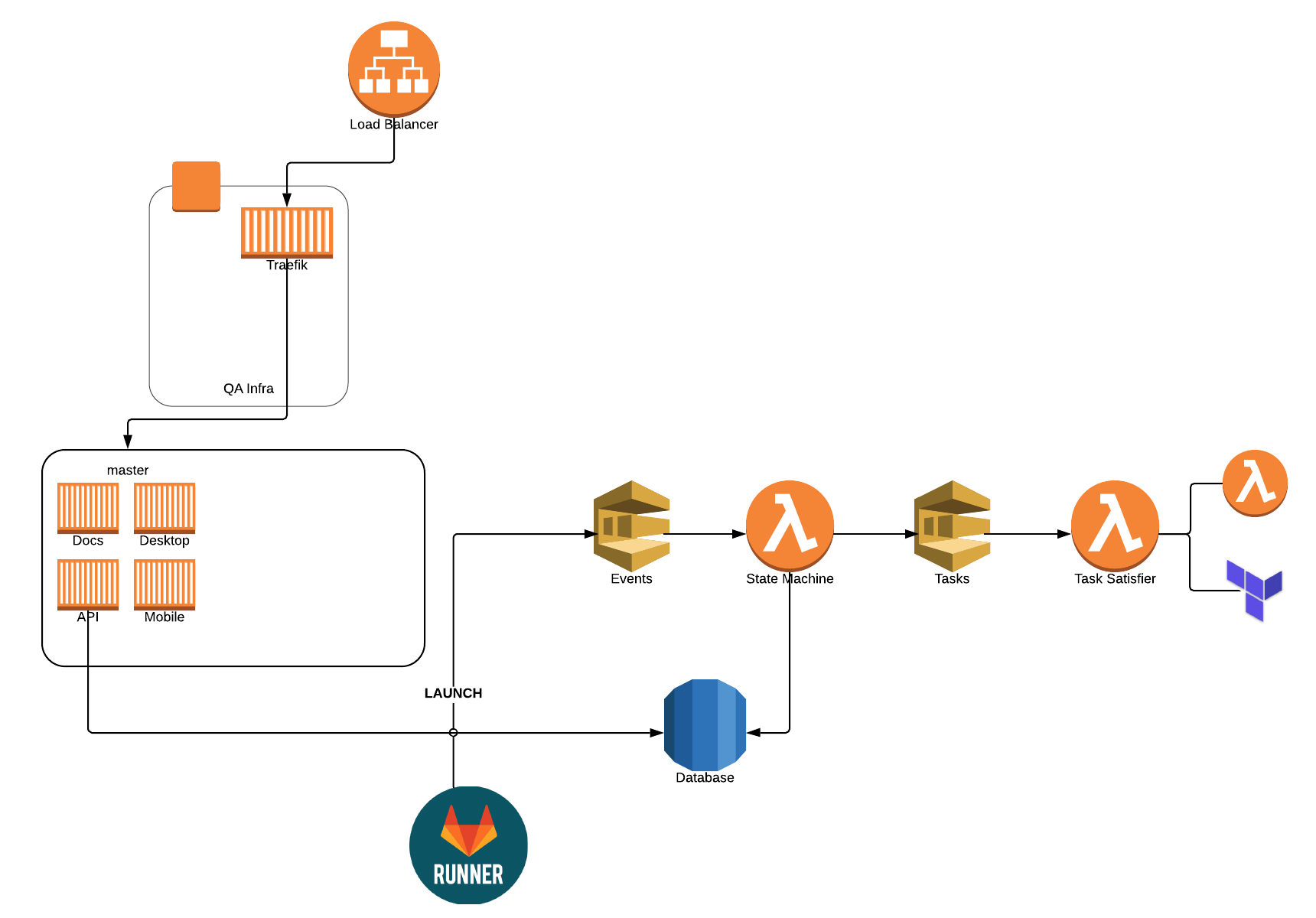
For each task that's needed, an event is published to a "tasks" SQS queue.
Another Lambda function processes each task. Tasks are executed in parallel using either Terraform or by invoking additional functions.
-
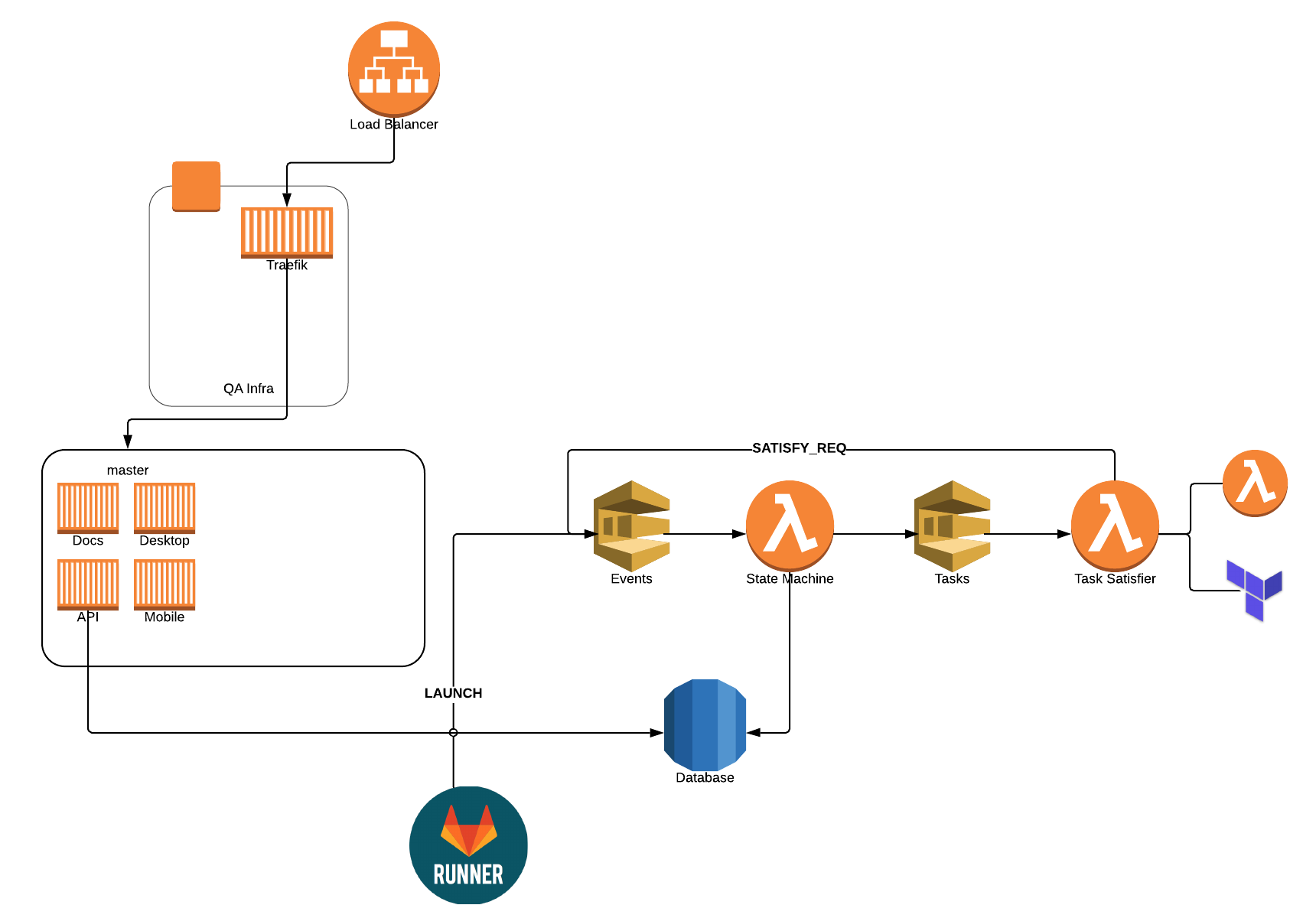
Upon completion, a
SATISFY_REQevent is published back to the "events" queue. The state machine will advance to the next state when all tasks are completed and eventually arrive at a stable state. -
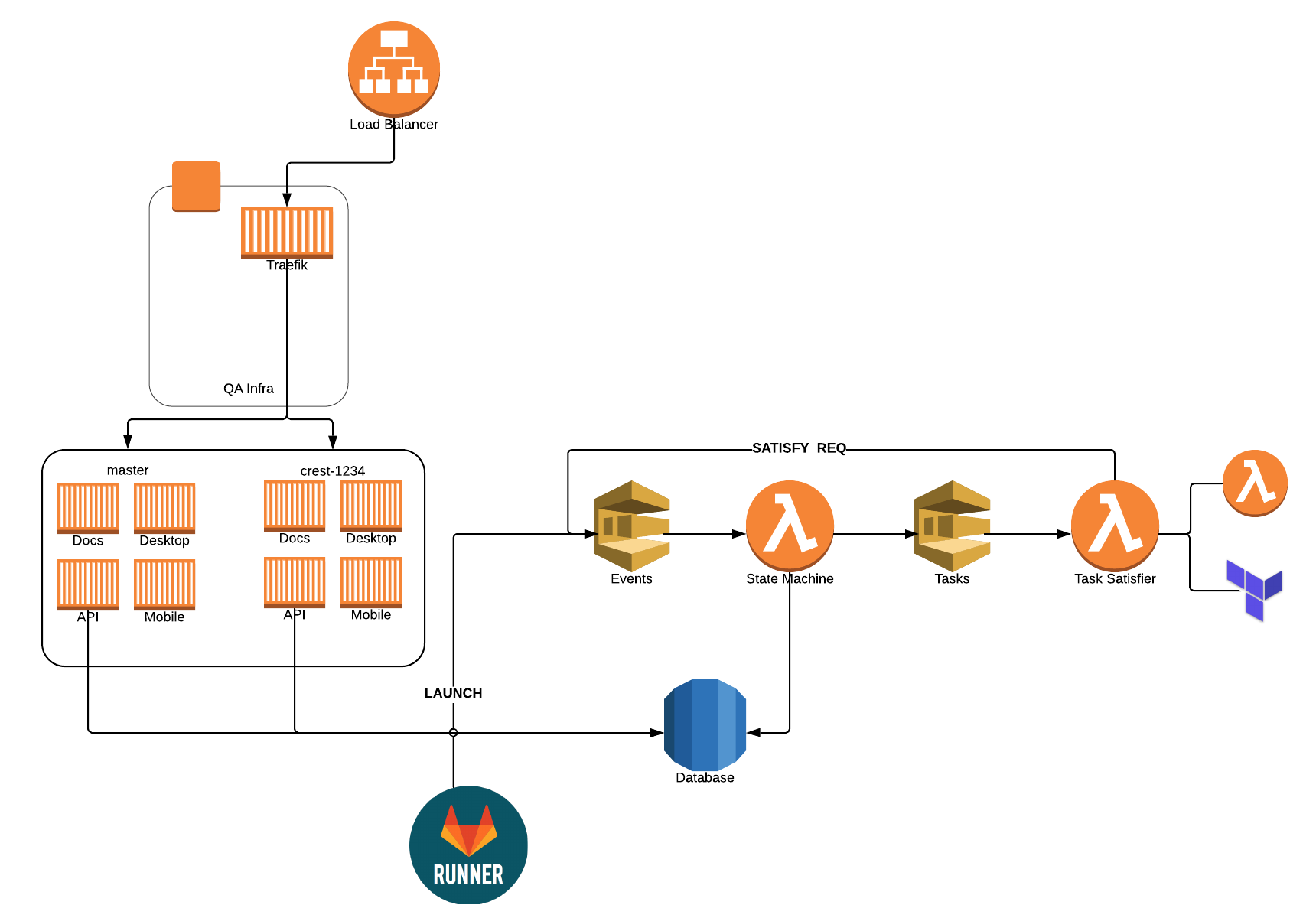
At this point, we have our new QA stack deployed! Traefik discovers the labels and will start sending traffic to it!
Then the question arises... how do we minimize costs? We don't need all of the stacks up all the time, right?
-
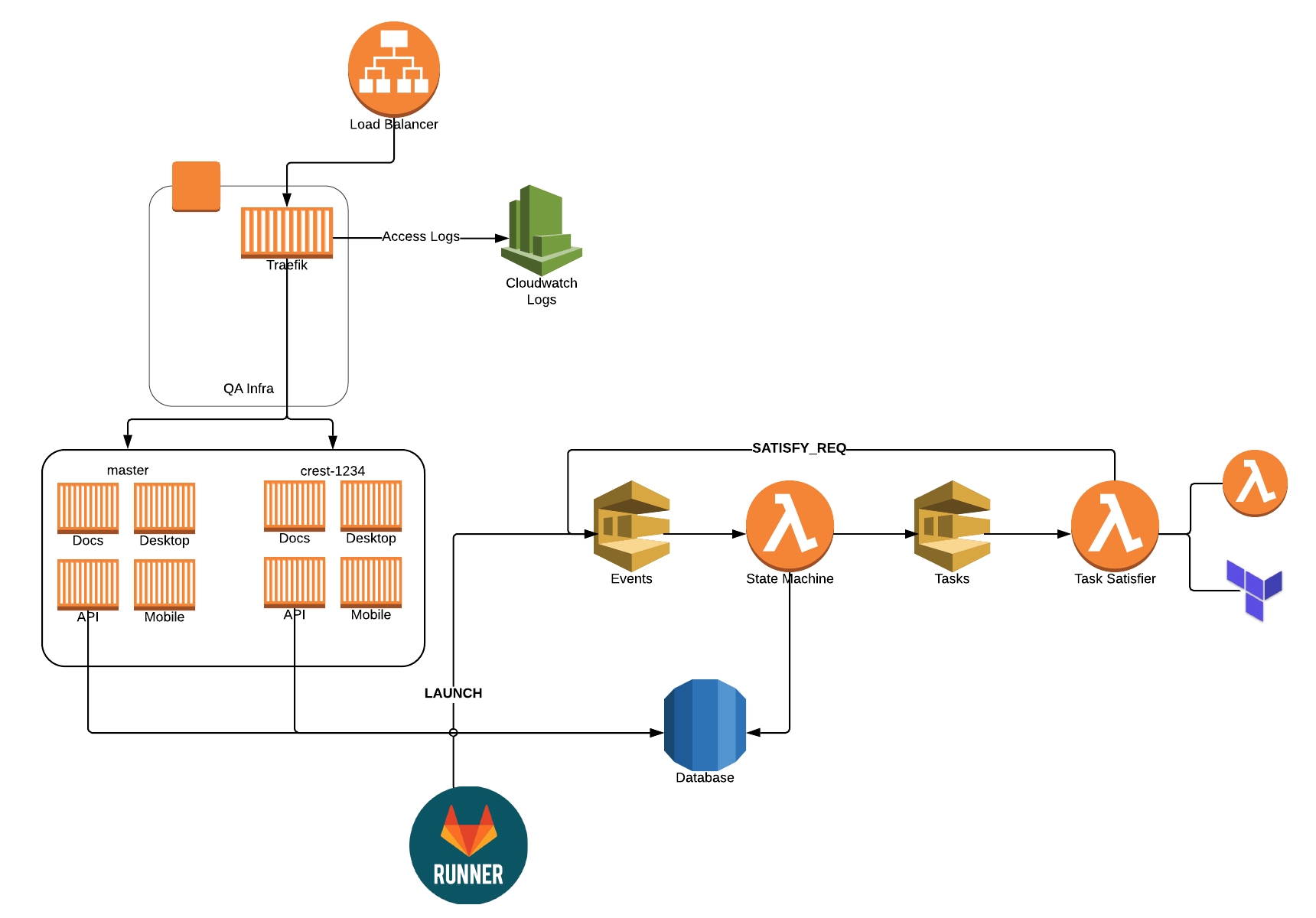
Since all requests to the QA environment go through Traefik, let's take advantage of that!
We simply send all access logs (in JSON format) to CloudWatch.
-
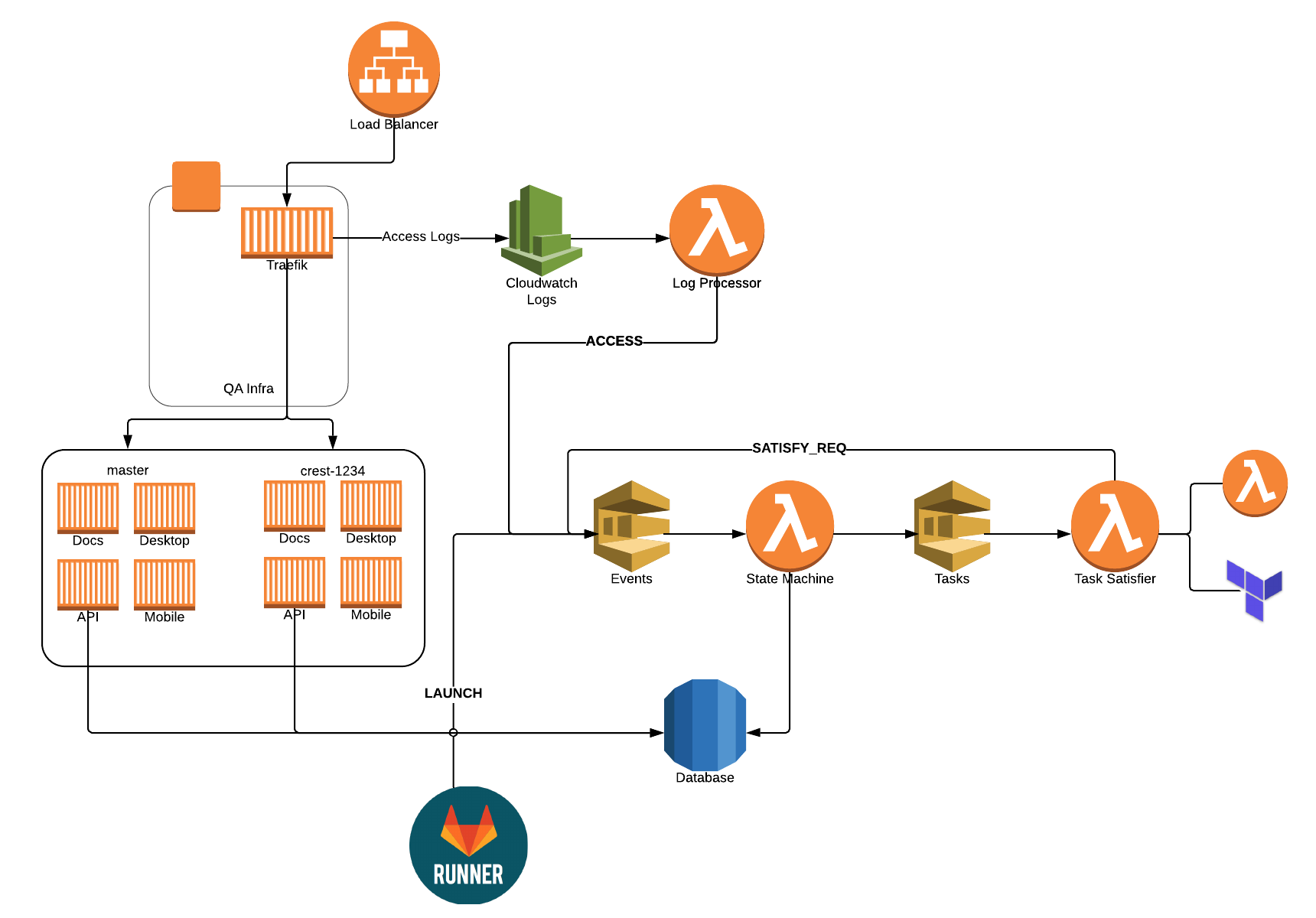
A CloudWatch subscription triggers a Lambda function that processes batches of access log messages. The function determines the stacks that were accessed and publishes an
ACCESSevent.The state machine stores the "last accessed time" as metadata for the stack.
-
On a periodic timer, we trigger another Lambda function, called the "Freezer." This function connects to the RDS database and looks for all stacks that haven't been accessed recently (for example, 30 minutes).
-
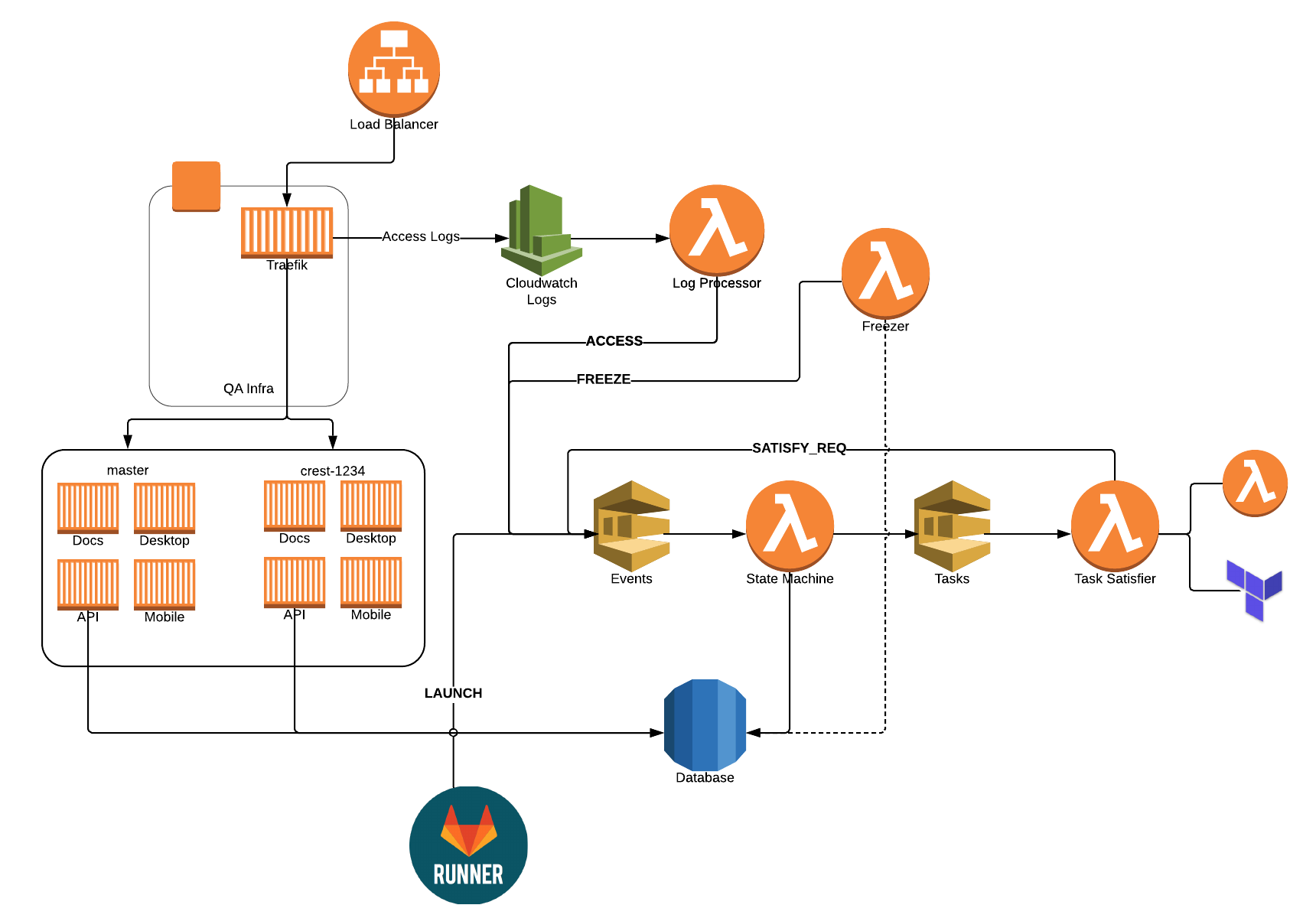
For each stack that hasn't been accessed recently, it publishes a
FREEZEevent. The state machine then executes tasks to update the ECS services for the stack to a desired count of 0. -
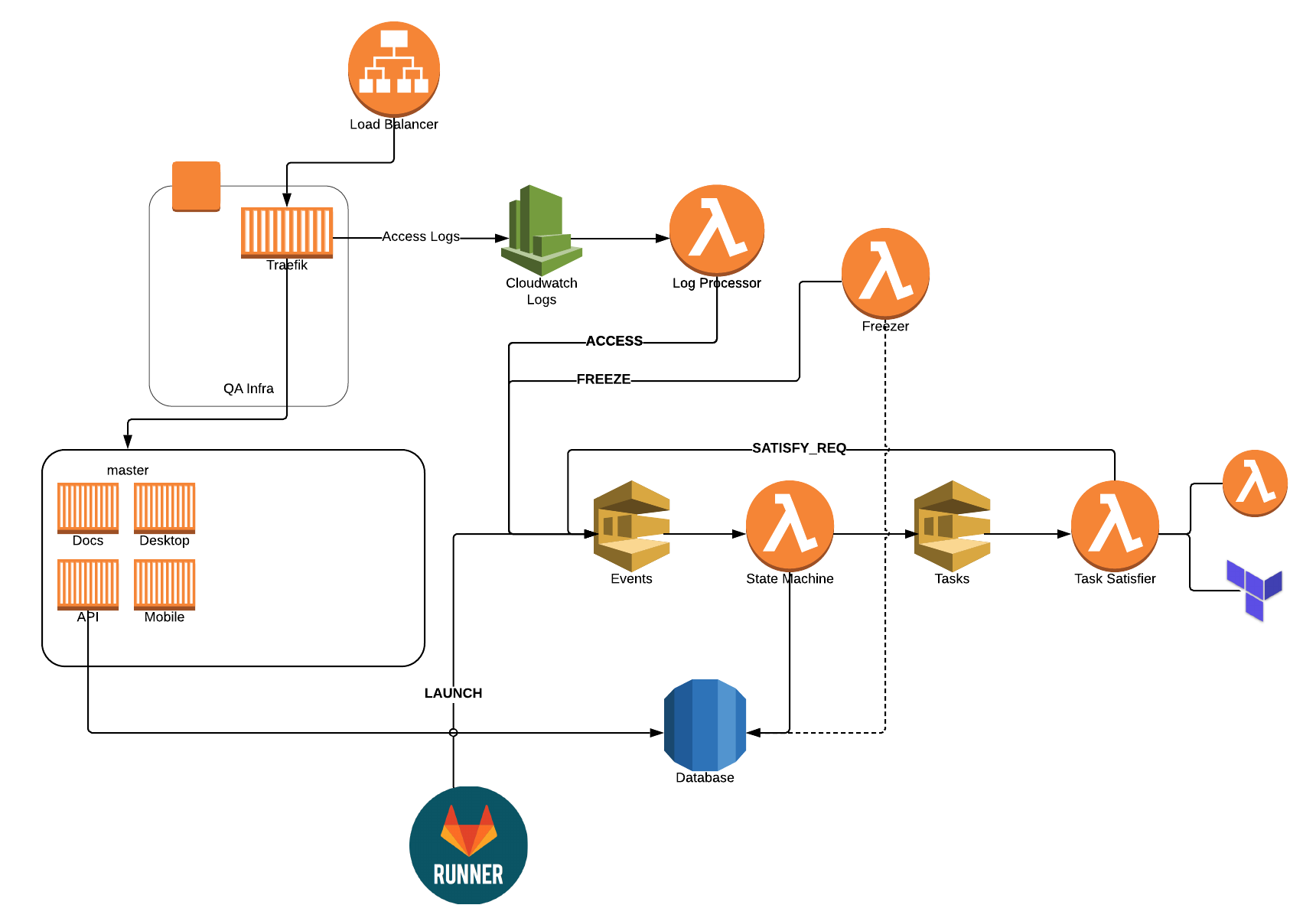
Before long, BOOM! The stack is scaled out and we're not incurring any costs!
But... what if our QA team wants to access that stack? Do they have to contact someone on the team to spin it back up? That would stink...
-
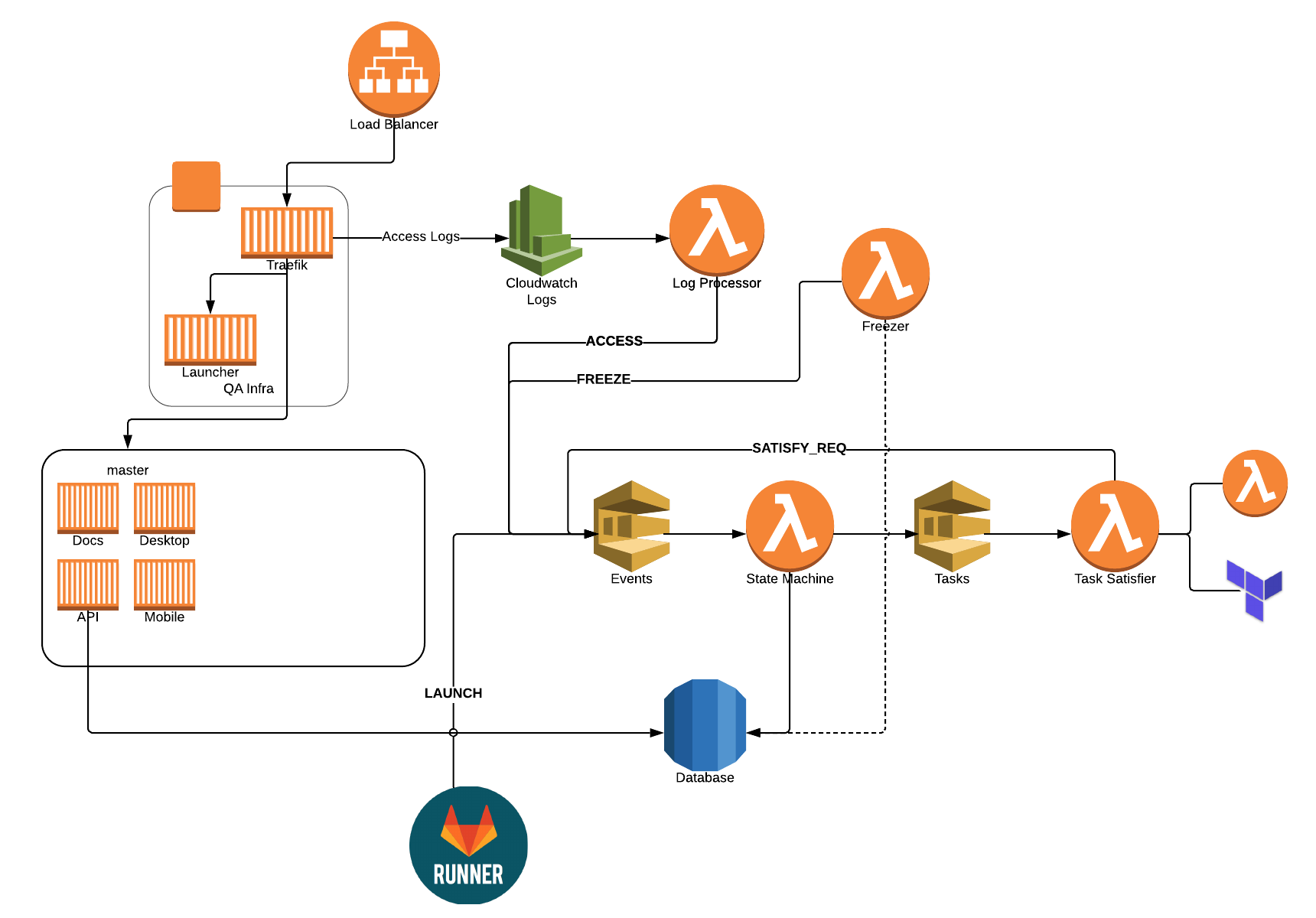
Using
traefik.frontend.prioritylabels on our containers, we can create a "fall-through" container for Traefik. Our actual stack containers have a higher priority, so take precedence. If a stack is not up, the "Launcher" handles the request (which has a low priority). -
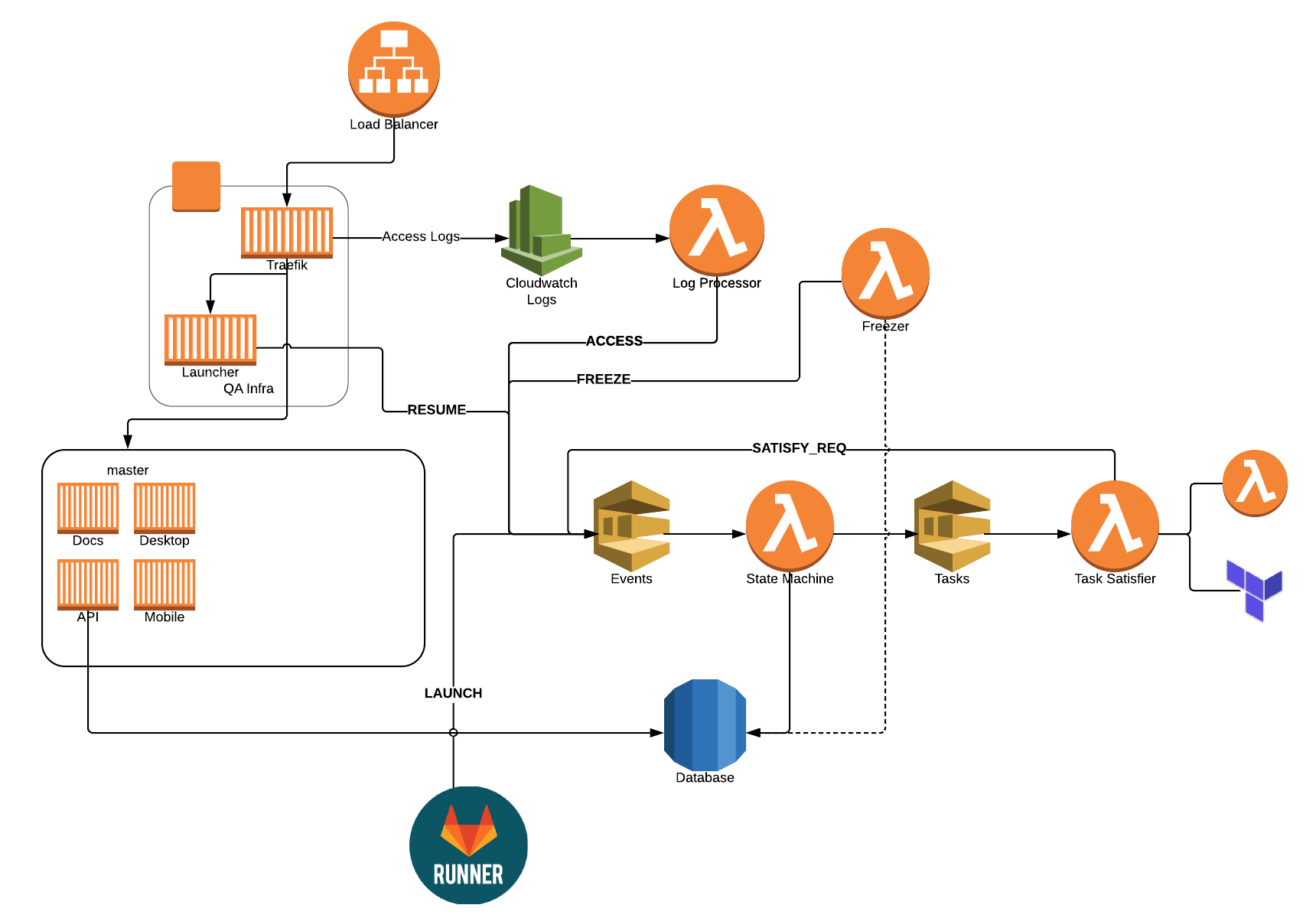
When a request comes in to the "launcher", it determines the stack for the requested host (each is on its own subdomain). If the stack is frozen, a
RESUMEevent is published.The state machine executes a task to scale the service back up and eventually...
-
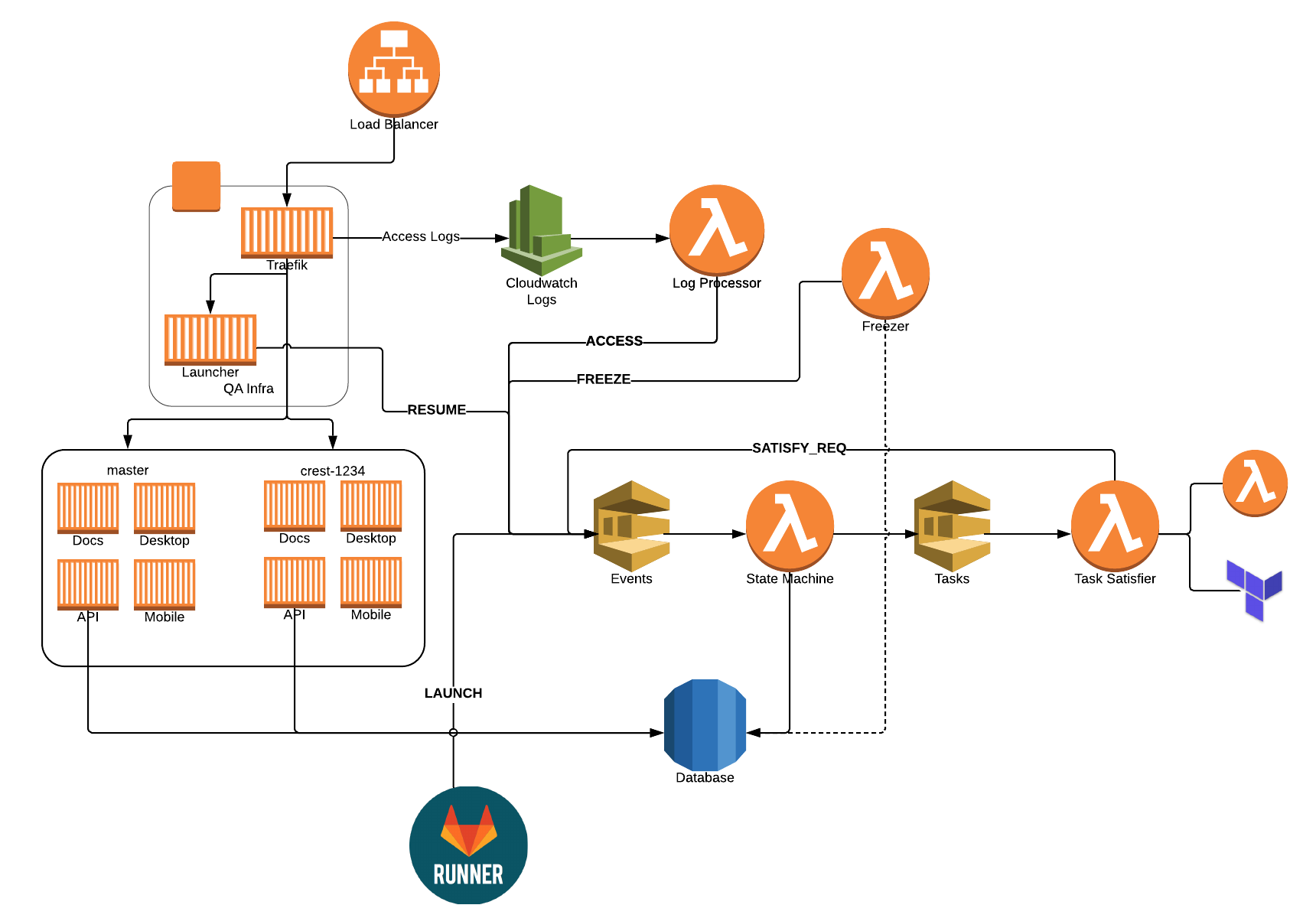
BOOM! The stack has spun back up, Traefik discovers it, and our QA team can continue testing.
With our applications, the elapsed time from sending a
RESUMEevent to a running application is about 2.5 minutes, most of which is starting the API.
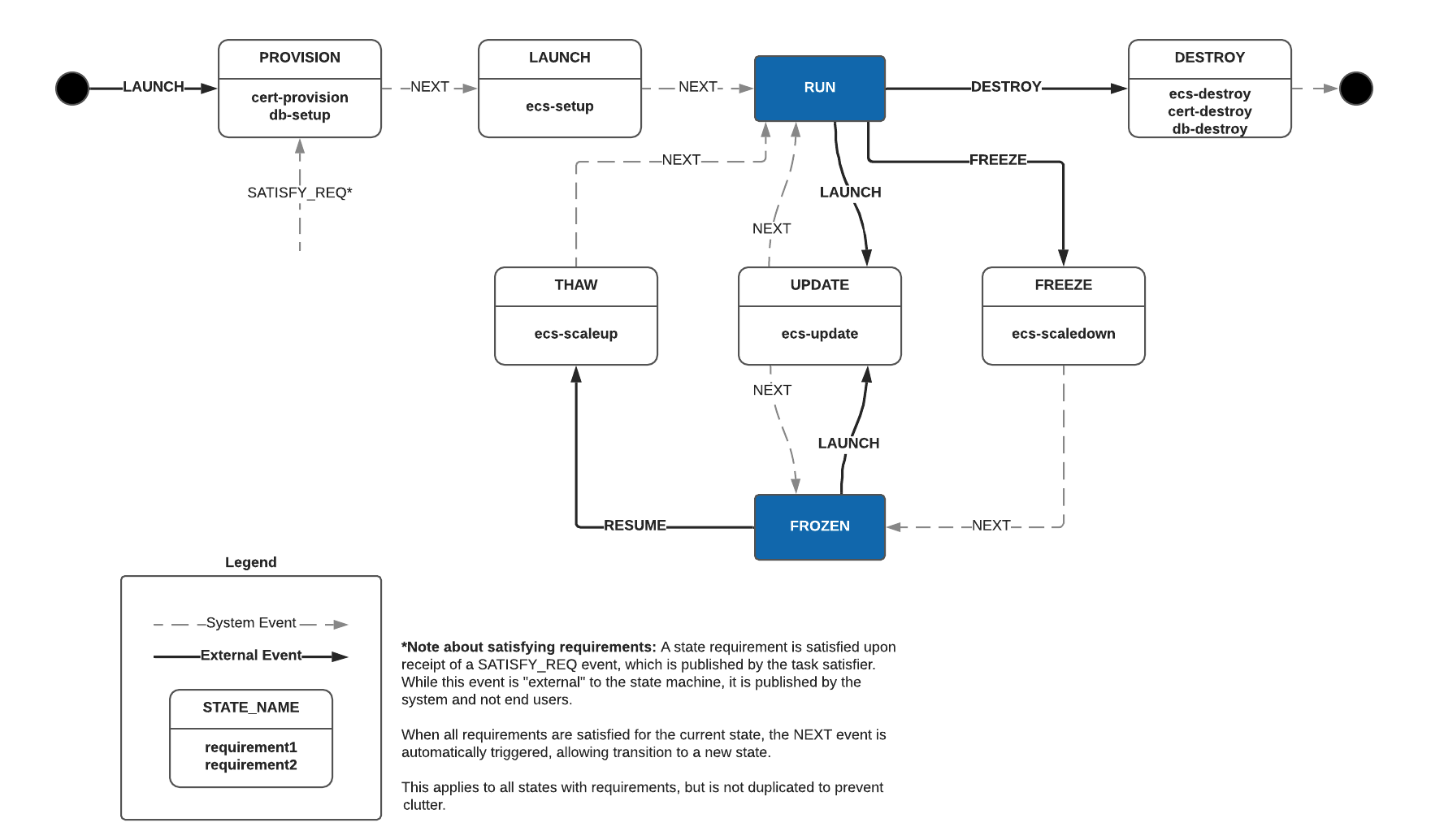
The State Machine
In case you're wondering what the full state machine looks like, here you go! In each state's box, it contains the tasks that are needed in order to advance to the next state. Click on it for a larger version.
Why Fargate?
When we first deployed the new environment back in December, we were actually spinning up an EC2 machine for each and every stack. It worked quite well, but in January, Fargate dropped their prices quite significantly. That made it a no-brainer to switch to Fargate. While no longer needing to manage infrastructure, it has significantly reduced the time to initially launch and resume a stack.
A few takeaways
We learned quite a few things, as this was our first endeavour leveraging this many AWS services and being this elastic and responsive. Here are a few items, in no particular order…
- None of this would have been possible without containers. If you're not using them yet, start now. The stacks are in containers. Traefik and the launcher are containers. It's containers everywhere. That's how you should do cloud.
- We're now big fans of Terraform. We used it setup the base infrastructure and to run several of our tasks.
- Fargate is awesome for on-demand environments that come and go. It's fast. It's quick. There's no infrastructure to worry about! Use it.
- Using SQS (and an event-driven design) was a great choice! If I ever needed to debug something, I could always open the SQS console, send a message manually, see what's in the queue, flush a queue. Make sure you setup a dead-letter queue to know when things fail too!
- Traefik is awesome… duh! We didn't have to think twice and haven't had a single issue with it the entire time.
- We set the concurrency for our state machine function to only 1, which makes a lot of the concurrency issues disappear. Responding to those events are fast, since most of the time is spent actually executing the tasks. For task completion, we let that scale as needed.
- Don't pre-optimize everything. When we thought about running Terraform scripts in Lambda, we were worried about how long it would take. They would easily fit into the time limits, but we were worried about the costs. After running it for a month or two, our Lambda bill hasn't crossed $0.25 for a single month yet. Good thing we didn't waste a lot of time over-optimizing it!
What's it cost? Was it worth it?
Overall, our QA environment has run at just over $100/month. Not bad for a team of six developers who range between 10-15 feature branches concurrently.
We didn't have a cost for what it took to run our QA environment on-prem, but we were frequently spending half a day trying to get the machine back under control due to over-utilization. Seeing that we've yet to spend any significant time in three months of operation in AWS, it's already been worth the effort in time saved.
What next?
We learned even more about how to manage state machines in the cloud using Lambda functions. But, that deserves a blog post of its own. So, be on the lookout for that!