In case you haven't seen, Karpenter is a new tool that manages the provisioning of nodes in your Kubernetes cluster. It uses a config-driven approach and attempts to pick the right node at the right time. It's pretty awesome!
For the platform team I've been working on, we've switched to use Karpenter as it's CRD-driven Provisioners make it easy to define node pools for each of our tenants. By the end of this post, you'll see how we 1) define the various node pools and 2) force tenant pods to run in their node pool.
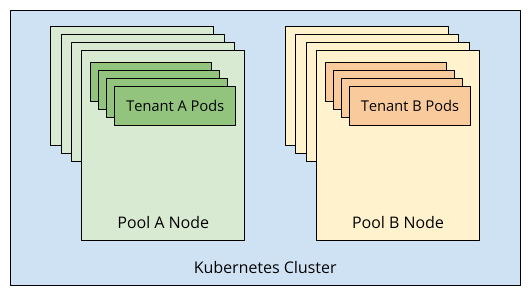
Our Scenario
To help out with this post, we're going to use the following scenario:
- We have two tenants, TenantA and TenantB, that need to run pods
- TenantA will use a namespace named
tenant-aand TenantB will use a namespace namedtenant-b - TenantA workloads must run in nodes part of PoolA and TenantB workloads should run in nodes part of PoolB
- Ideally, TenantA and TenantB are completely unaware this is even happening and don't need to do anything in their pod specs to schedule their pods in the right location
Let's first create namespaces for TenantA and TenantB:
kubectl create namespace tenant-a
kubectl create namespace tenant-b
Defining Node Pools
First off, there's no true concept of a node pool within Karpenter. It's simply spinning up and tearing down nodes. But, we can make node pools ourselves using a combination of taints/tolerations and node labels. The idea is as follows:
- Nodes in PoolA will have:
- A
NoScheduletaint with keynode-pooland valuepool-a - A label with key
node-pooland valuepool-a
- A
- Nodes in PoolB will have:
- A
NoScheduletaint with keynode-pooland valuepool-b - A label with key
node-pooland valuepool-b
- A
The taint prevents kube-scheduler from scheduling pods onto the node unless the pod specifically says its ok using a toleration. The label lets us force the pod onto the node using a nodeSelector or nodeAffinity.
So… how do we do this using Karpenter? Assuming you followed one of the Getting Started guides, we can define PoolA with the following Provisioner:
cat <<EOF | kubectl apply -f -
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: pool-a
spec:
taints:
- key: node-pool
value: pool-a
effect: NoSchedule
labels:
node-pool: pool-a
ttlSecondsAfterEmpty: 30
provider:
subnetSelector:
karpenter.sh/discovery: ${CLUSTER_NAME}
securityGroupSelector:
karpenter.sh/discovery: ${CLUSTER_NAME}
instanceProfile: KarpenterNodeInstanceProfile-${CLUSTER_NAME}
EOF
And we can define PoolB with the following (simply changing values for the taint and label):
cat <<EOF | kubectl apply -f -
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: pool-b
spec:
taints:
- key: node-pool
value: pool-b
effect: NoSchedule
labels:
node-pool: pool-b
ttlSecondsAfterEmpty: 30
provider:
subnetSelector:
karpenter.sh/discovery: ${CLUSTER_NAME}
securityGroupSelector:
karpenter.sh/discovery: ${CLUSTER_NAME}
instanceProfile: KarpenterNodeInstanceProfile-${CLUSTER_NAME}
EOF
Tip: By using spec.provider.tags, you can add additional tags on the EC2 instances Karpenter launches. If you use Cost Allocation Tags, you can have an idea of the costs incurred by each node pool.
Forcing Pods into their Pools
In order to force pods into their respective node pools, we are going to take advantage of admission controllers and mutate the pod to add a nodeSelector and tolerations to the spec. By using a nodeSelector, it allows teams to still define their own nodeAffinity to provide additional guidance on how Karpenter should provision nodes.
Rather than writing our own admission controller, we're going to use Gatekeeper and its mutation support. Let's first install Gatekeeper!
helm repo add gatekeeper https://open-policy-agent.github.io/gatekeeper/charts
helm install gatekeeper/gatekeeper --name-template=gatekeeper --namespace gatekeeper-system --create-namespace
With Gatekeeper installed, we want to create a mutation policy that will define a nodeSelector for all pods in the tenant-a namespace to use the nodes in pool-a. Let's create an Assign object to do that!
cat <<EOF | kubectl apply -f -
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: nodepool-selector-pool-a
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["tenant-a"]
location: "spec.nodeSelector"
parameters:
assign:
value:
node-pool: "pool-a"
EOF
And now let's create another mutation to give all pods in the tenant-a namespace the toleration that allows them to run on the nodes in PoolA:
cat <<EOF | kubectl apply -f -
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: nodepool-toleration-pool-a
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["tenant-a"]
location: "spec.tolerations"
parameters:
assign:
value:
- key: node-pool
operator: "Equal"
value: "pool-a"
EOF
And now we can do the same thing for PoolB (script below defines both objects in a single command):
cat <<EOF | kubectl apply -f -
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: nodepool-selector-pool-b
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["tenant-b"]
location: "spec.nodeSelector"
parameters:
assign:
value:
node-pool: "pool-b"
---
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: nodepool-toleration-pool-b
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["tenant-b"]
location: "spec.tolerations"
parameters:
assign:
value:
- key: node-pool
operator: "Equal"
value: "pool-b"
EOF
Testing it Out
Now that we have our node pools defined and the mutation support plugged in, let's create a pod for each of our tenants and make sure it works.
kubectl run --image=nginx:alpine --namespace tenant-a nginx
kubectl run --image=nginx:alpine --namespace tenant-b nginx
Once you do this, you should two new nodes start up, thanks to Karpenter! Note that it might take a moment or two for the nodes to startup and join the cluster.
> kubectl get nodes --selector=node-pool -L node-pool
NAME STATUS ROLES AGE VERSION NODE-POOL
ip-192-168-50-153.ec2.internal Ready <none> 85s v1.21.5-eks-bc4871b pool-a
ip-192-168-64-221.ec2.internal Ready <none> 83s v1.21.5-eks-bc4871b pool-b
And if you look at the pods and where they are running, you'll see they are on their respective nodes!
> kubectl get pods -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
...
tenant-a nginx 1/1 Running 0 7m39s 192.168.54.64 ip-192-168-50-153.ec2.internal <none> <none>
tenant-b nginx 1/1 Running 0 5m57s 192.168.68.73 ip-192-168-64-221.ec2.internal <none> <none>
Additional Customization
Since we are setting a nodeSelector and the tolerations, the teams defining pods in those namespaces won't be able to use either of those fields. But, they are able to use the nodeAffinity to further influence where pods will be scheduled, and thus instrumenting how Karpenter might spin up additional nodes.
As an example, the following pod definition will create a pod in PoolA, but use a m5.large instance.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: arm64-spot-test
namespace: tenant-a
spec:
containers:
- name: nginx
image: nginx:alpine
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- m5.large
EOF
After a moment, you'll see a new m5.large instance join your cluster! If you want to allow your teams to choose spot or on-demand, amd64 or arm64, or other combinations, you only need to ensure your Provisioner specifies the appropriate requirements (Karpenter currently sets defaults that does limit the types of nodes you can have if no requirements are specified).
Cleaning Up
If you were following and trying it out yourself, you can run the following to clean up your resources:
kubectl delete ns tenant-a tenant-b
kubectl delete nodes --selector=node-pool
eksctl delete iamserviceaccount --cluster ${CLUSTER_NAME} --name karpenter --namespace karpenter
aws cloudformation delete-stack --stack-name Karpenter-${CLUSTER_NAME}
aws ec2 describe-launch-templates \
| jq -r ".LaunchTemplates[].LaunchTemplateName" \
| grep -i Karpenter-${CLUSTER_NAME} \
| xargs -I{} aws ec2 delete-launch-template --launch-template-name {}
eksctl delete cluster --name ${CLUSTER_NAME}
Wrap-up
That's it! By using the combination of taints/tolerations and node labels, we are able to create various node pools to help isolate various tenant workloads. Combining that with Gatekeeper's mutation support, tenants don't have to make any modifications to their pod specs and they can't have their workloads run in another tenant's pool.
For our platform team, we created a Helm chart that makes it easy to define all of this config (as well as additional tenant config). If you're interested in learning more about that, check out my Making Kubernetes Multi-Tenant blog post.
If you have any questions and/or feedback, feel free to share it below! Thanks for reading!