Making Kubernetes Multi-Tenant
Building a platform or "containers-as-a-service" is very appealing to development teams - they can simply build containers and never worry about infrastructure again! While trying to build VT's platform, I often was advised and pushed to do multi-tenancy by going multi-cluster. But, that's a significant overhead in cost, maintenance, and support, especially when each cluster is basically the same (it does make sense to use different clusters for different needs though). Instead, we tried to figure out how to make multi-tenancy work within a single cluster. This blog post highlights the major pillars that make it all possible.
Defining a Tenant
For us, the definition of a tenant is very loose. It might be an entire team. Or an environment (prod vs dev). Or a single application. Or even an environment for a specific application (prod vs dev for an app). To us, as a platform team, we don't really care. We treat them all the same and give our application teams the choice on how they want to divide their workloads.
When mapping to Kubernetes, each tenant has its own namespace.
The Four Tenets of Multi-Tenancy
The four tenets describe the major components on making multi-tenancy work. Each block adds to the previous, but any missing blocks introduce gaps in protection. We'll dive into each one in greater detail later in the post.
- Network Isolation - ensure applications can't talk to each other unless explicitly authorized to do so
- Node pooling - to reduce noisy neighbor problems, provide better cost accounting, and a greater security boundary, various pools of nodes should be used for tenants
- Identity and Access Management - tenants need the ability to both make changes in the cluster and query resources
- Additional Policy Enforcement - the built-in RBAC in Kubernetes provides a lot of support, but needs additional policy control to ensure tenants cannot step on each others' toes
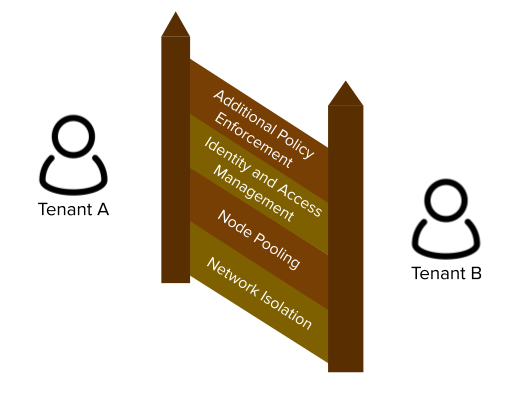
Tenet #1 - Network Isolation
For our platform, we want to ensure applications in different tenants/namespaces can't reach each other in-cluster. We want to support an "out-and-back" approach, meaning all requests would go out of the cluster, through the external load balancer, and through the ingress controller to land at the right application.
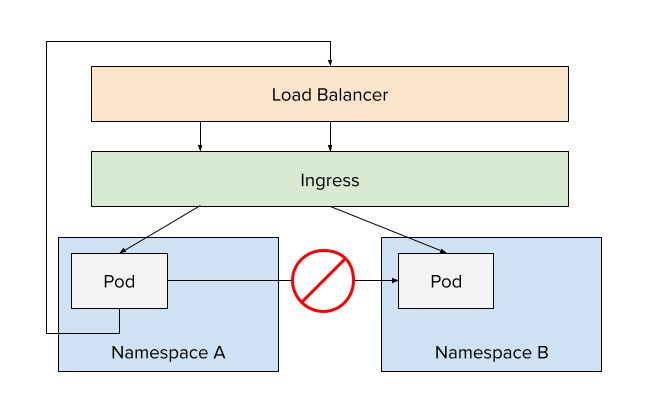
The only exception to this would be platform services. For example, the Ingress controller obviously needs to send traffic across namespaces. The same would be true for a central Prometheus instance scrapping metrics from tenant applications.
To pull this off, you have to look at the specific CNI (Container Network Interface) you are using in your cluster. For us, we're using Calico. As such, we would simply define a network policy that restricts traffic across namespaces. The policy below denies all network ingress from namespaces that have the specified label (which is one we place on all tenant namespaces).
apiVersion: crd.projectcalico.org/v1
kind: NetworkPolicy
metadata:
name: restrict-other-tenants
namespace: test-tenant
spec:
order: 20
selector: ""
types:
- Ingress
ingress:
- action: Deny
source:
namespaceSelector: platform.it.vt.edu/purpose == 'platform-tenant'
As you can see, this policy is applied per tenant within their namespace. We specifically chose to use an ingress rule to potentially allow tenants to define their own policies with a higher order that does allow traffic from namespaces. Had we chose to use egress rules, there's a chance a tenant creates an egress rule that starts flooding another tenant that isn't wanting the traffic.
Tenet #2 - Node Pooling
One of the main concerns we heard from customers was the idea that a misbehaving pod might negatively impact their applications. In addition, after discussions with our senior leadership, they expressed the desire to have an idea of cost accounting to know how much each application is costing. A compromise we landed on was to create various node pools for one or more tenants to share. There's the obvious trade-off that as you create more/smaller node pools, you sacrifice utilization and increase overhead from system pods (log aggregators, volume plugins, Prometheus exporters, etc.).
Defining the Node Pools
To support node pooling, we originally started with the Cluster Auto-scaler project. But, we ran into limitations…
- We needed to define many auto-scaling groups for each node pool
- How should we support EBS volumes (an ASG per AZ?)?
- How can we support mixed types (scheduling some on-demand and some spot instances) and sizes?
- How can we reduce the amount of shared/“magic” names? The ASGs were defined in one repo, far removed from where the tenant config itself was defined.
For us, Karpenter has been a huge benefit. While there are still a few shortcomings, it's super nice being able to define the node pools simply using K8s objects.
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: example-pool
spec:
taints:
- key: platform.it.vt.edu/node-pool
value: example-pool
effect: NoSchedule
# Scale down empty nodes after low utilization. Defaults to an hour
ttlSecondsAfterEmpty: 300
# Kubernetes labels to be applied to the nodes
labels:
platform.it.vt.edu/cost-code: platform
platform.it.vt.edu/node-pool: example-pool
kubeletConfiguration:
clusterDNS: ["10.100.10.100"]
provider:
instanceProfile: karpenter-profile
securityGroupSelector:
Name: "*eks_worker_sg"
kubernetes.io/cluster/sample-cluster: owned
# Tags to be applied to the EC2 nodes themselves
tags:
CostCode: platform
Project: example-pool
NodePool: example-pool
A few specific notes worth mentioning…
- We specifically put taints on all tenant node pools so pods don't accidentally get scheduled on them without specifying tolerations (more on that in a moment)
- We tag the EC2 machines with various tags, including a few Cost Allocation Tags. The
CostCodeis a pseudo-organization level tag while theProjectis a specific project/tenant name. This allows us to use multiple node pools for the same organization. - Since we are using the Calico CNI, we need to specify the clusterDNS address.
Forcing Pods into their Node Pools
Simply defining a node pool doesn't mean that tenants will use it. And, as a platform team, we don't want teams to have to worry about the pools at all. It would be best if it were completely invisible to them.
Using the Gatekeeper Mutation support, we can define a policy that will mutate all pods to add a nodeSelector and toleration to ensure the pods are scheduled into the correct pool. And… it's done in a way that ensures tenants can't get around it. By using nodeSelectors, tenants can use the nodeAffinity config to provide Karpenter more configuration (to use spot instances, ARM machines, etc.).
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: example-tenant-nodepool-selector
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["example-tenant"]
location: "spec.nodeSelector"
parameters:
assign:
value:
platform.it.vt.edu/node-pool: example-pool
---
apiVersion: mutations.gatekeeper.sh/v1beta1
kind: Assign
metadata:
name: example-pool-nodepool-toleration
namespace: gatekeeper-system
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
namespaces: ["example-tenant"]
location: "spec.tolerations"
parameters:
assign:
value:
- key: platform.it.vt.edu/node-pool
operator: "Equal"
value: "example-pool"
With this, all Pods defined in the example-tenant namespace will have a nodeSelector and toleration added that will force the Pod to run on nodes in the example-pool node pool. Karpenter will manage the nodes and scale up and down as needed.
Tenet #3 - Identity Access and Management
In order to run a successful platform, we want to ensure the platform team is not a bottleneck to deploying updates or troubleshooting issues. As such, we want to give as much control back to the teams, but do so in a safe way.
Making Changes to the Cluster
For our platform, we are using Flux to manage the deployments. Each tenant is given a "manifest repo" where they can update manifests and have them applied in the cluster. This prevents the need to distribute credentials for CI pipelines to make changes, etc. By leveraging webhooks, changes are applied very quickly.
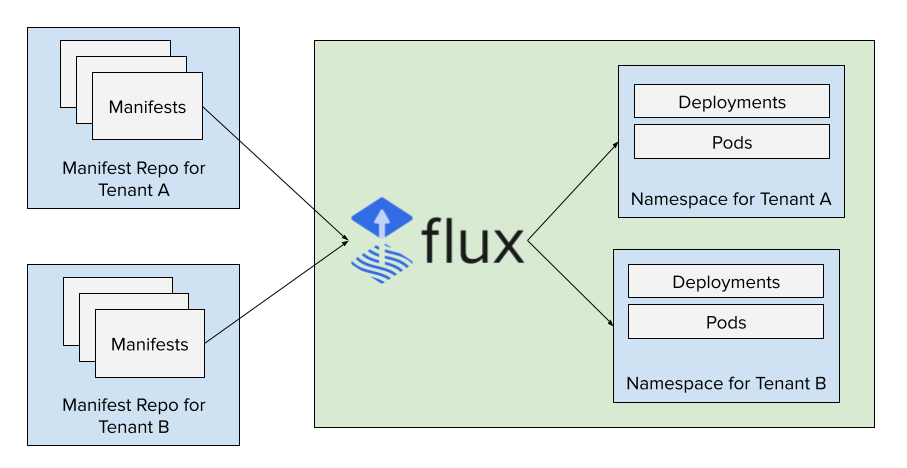
Providing Read-only Access to the Cluster
To allow teams to troubleshoot and debug issues, we provide the ability for them to query their resources in a read-only manner. We're currently using the following tools to pull it off:
- Dex - a Federated OpenID Provider that performs authentication of users. We have this configured as an OAuth client to our central VT Gateway service, ensuring all auth is two-factored and backed by our VT identity systems
- Kube OIDC Proxy - this serves as an API proxy that uses the tokens issues by Dex as authentication. It then impersonates the requests to the underlying k8s API, passing along the user's username and group memberships.
With those two deployed, we can then create RoleBinding objects that authorize specific groups (from our central identity system) to have read-only access to specific namespaces (defined in a ClusterRole named platform-tenant).
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: tenant-access
namespace: example-tenant
subjects:
- kind: Group
name: oidc:sample-org.team.developers
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: platform-tenant
apiGroup: rbac.authorization.k8s.io
The big advantage of using the Kube OIDC proxy is that we can share the OIDC tokens and allow users to configure their local Kubeconfig files with the same credentials, allowing them to use kubectl and other tools for additional querying.
We've also built a dashboard that is a client of the Dex OIDC provider. As user's authenticate, the dashboard simply forwards the logged-in user's tokens to the API to query the resources. That makes our dashboard completely unprivileged and removes any ability of a user seeing something they shouldn't be able to see.
Tenet #4 - Additional Policy Enforcement
While the built-in Kubernetes RBAC provides a lot of capability, there are times in which we want to get more granular. A few examples:
- Tenants should be able to create Services, but how can we prevent them from creating NodePort or LoadBalancer Services?
- How do we limit the domains one tenant can use for Ingress/Certification objects so they don't intercept the traffic meant for another?
- How can we enforce the Pod Security Standards to prevent pod from gaining access to the underlying host?
Fortunately, we can use admission controllers to plug in our own policies as part of the API request process. Rather than writing our own services, we can leverage Gatekeeper and write OPA policies. And with OPA, we can easily write unit tests to catch and prevent regressions.
If you're not familiar with Gatekeeper, it's basically a wrapper around the OPA engine that allows us to write our policies with Kubernetes objects and run them whenever objects are being created or updated in the cluster. In addition, we can apply the same policies in different ways for different tenants.
As an example, a ConstraintTemplate that defines an AuthorizedDomainPolicy could then be used to define the authorized domains for each namespace. The sample object below will enforce that policy in the example-tenant namespace and ensure we only use the specified names. To help with on-boarding, we also automatically authorize <tenant-id>.tenants.platform.it.vt.edu to be used by each tenant. They are welcome to CNAME any other name and point to the cluster to use more friendly names. All we have to do is update their policy.
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: AuthorizedDomainPolicy
metadata:
name: example-tenant
spec:
match:
namespaces:
- example-tenant
kinds:
- apiGroups: ["extensions", "networking.k8s.io"]
kinds: ["Ingress"]
- apiGroups: ["cert-manager.io"]
kinds: ["Certificate"]
parameters:
domains:
- example-tenant.tenants.platform.it.vt.edu
- "*.example-tenant.tenants.platform.it.vt.edu"
- smaller-url.example.com
Putting it All Together
While it feels like there's a lot to define for each tenant, it's very repetitive. Once we had defined a few tenants, we were able to figure out how to build a Helm chart that defines all of the various objects for each tenant. All we have to do is build and use a values file that defines the tenants, their config, and the node pools. An example values file is below. Today, the values for each cluster is stored in Git, but eventually, it might be sourced and built from a developer portal (maybe Backstage???).
global:
clusterHostname: cluster.hostname
tenantHostPrefix: tenants-example.platform.it.vt.edu
clusterName: vt-common-platform-dvlp-cluster
clusterDNS: 10.1.0.10
nodePools:
sample-team-apps:
instances:
capacityTypes: ["on-demand"]
instanceTypes: ["t3a.large"]
costCode: org1
sample-team-gitlab-jobs:
instances:
capacityTypes: ["on-demand", "spot"]
instanceTypes: ["t3a.medium"]
emptyTtl: 600
ttl: 604800
costCode: org1
tenants:
sample-team-gitlab-ci:
nodePool: sample-team-gitlab-jobs
operatorEdGroup: team.devs.platform-access
nis-customer-portal:
nodePool: sample-team-apps
operatorEdGroup: team.devs.platform-access
domains:
- sample-team.org.vt.edu
- "*.sample-team.org.vt.edu"
Wrapping Up
I know there's a lot of material here. If you're interested in learning more, I'm happy to do follow-up posts. Let me know what sounds interesting and what you want to read more about.