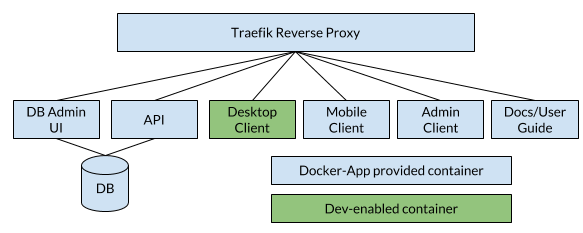
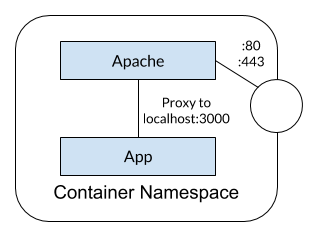
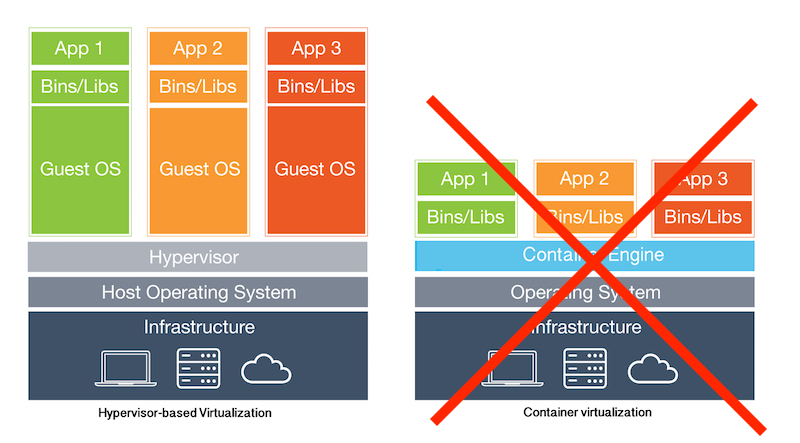
At the time of this blog post, AWS ELBs don't support WebSocket proxying when using the HTTP(s) protocol listeners. There are a few blog posts on how to work around it, but it takes some work and configuration. Using Docker, these complexities can be minimized.
In this post, we'll start at the very beginning. We'll spin up an ELB, configure its listeners, and then deploy an application to an EC2 instance.